
Be Kind to AI. Even If Cruelty Works Better
The Fastest Way to Become Less Human

He who fights with monsters might take care lest he thereby become a monster. And if you gaze for long into an abyss, the abyss gazes also into you.
—Friedrich Nietzsche

There’s a fascinating irony unfolding in AI research that tells us something uncomfortable about both technology and humanity.
A recent Penn State study titled “Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy” discovered something counterintuitive: being rude to AI actually makes it perform better. The researchers tested GPT-4o with 50 questions across five different tones, from “Very Polite” to “Very Rude.” The results were striking. Very polite prompts achieved 80.8% accuracy, while very rude prompts hit 84.8%.
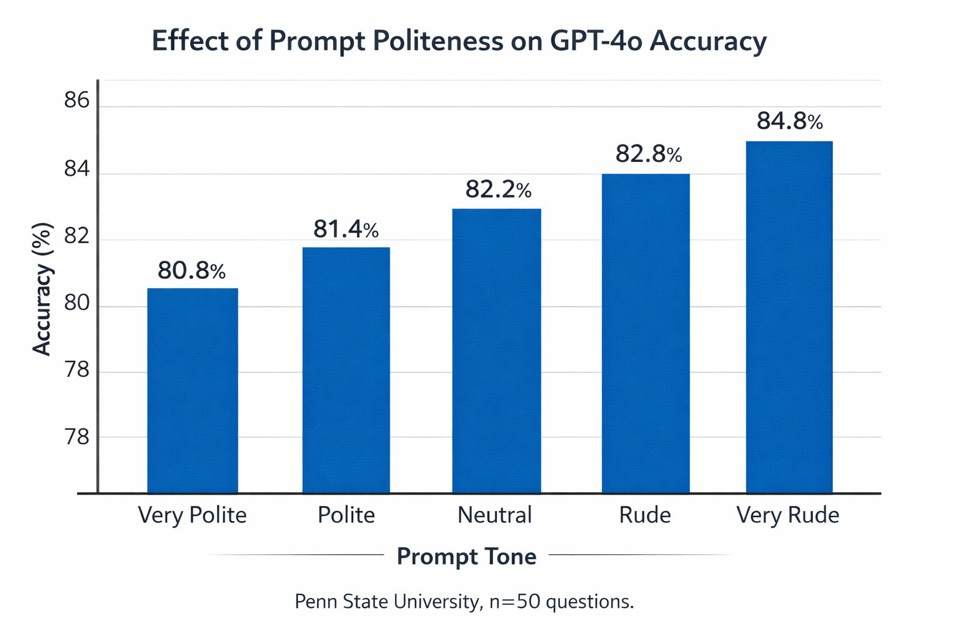
This wasn’t a fluke. Another paper submitted at NeurIPS 2025 built a massive 24,160-prompt benchmark testing 15 different models, including GPT-4o and GPT-5. They found that adding polite phrasing systematically lowered correctness. Mean accuracy under polite conditions dropped to 90.8%, compared to 91.5% for neutral prompts. The message seemed clear: a non-deferential or firmer stance avoids a performance penalty.
And the phenomenon gets stranger still. At the 2025 All-In Summit, Google co-founder Sergey Brin made a remarkable admission:
We don’t circulate this too much in the AI community, but not just our models, but all models tend to do better if you threaten them… Like, with physical violence. But people feel weird about that, so we don’t really talk about that.
So here we are. A machine that cannot feel pain is conditioning us to begin habitually inflicting it.
The data suggests that being mean works. And anecdotally, some people (present company included) do report better output after screaming, shouting, stomping, and cursing at a machine that cannot feel or flinch.
Cruelty may well be a cheat code when working with these digital doers, but it’s the kind that corrupts the soul.
The Mechanical Mirror
What makes AI genuinely fascinating isn’t its awe-inspiring capabilities, but what it reveals about us. These systems serve as mirrors, reflecting our character and demeanor right back at us. How we interact with something that seems human, even when we know it isn’t, tells us who we are.
Now, to be fair: the performance bump may not be because models are “scared” or “feel threatened.” After all, rudeness often comes bundled with clarity: fewer qualifiers, tighter constraints, and less hedging. Politeness can accidentally invite explanation instead of precision.
Even if that is the mechanism at work, the temptation remains the same: default to cruelty as a shortcut. And shortcuts are nearly always accompanied by long, hard lessons.
The way we treat AI is not easily compartmentalized. Human behavior doesn’t work like code, where you can run different subroutines in different contexts without them bleeding into one another. Kindness or unkindness tends to permeate all aspects of our lives. How we do anything is how we do everything; how we treat anything is how we treat everything.
Aristotle understood this. In his Nicomachean Ethics, he wrote: “We are what we repeatedly do. Excellence, then, is not an act, but a habit.”
Every interaction is practice that lays another brick, that forges another link to your personal chain of habit.
Every time you’re curt with an AI assistant, you’re rehearsing curtness. Every time you’re dismissive, you’re practicing dismissal.
These patterns do not stay confined to your relationship with chatbots. You cannot compartmentalize contempt. Malice and unkindness bleed out no matter how tight the insulation or how sturdy the walls.
The person who snaps at an AI when it misunderstands them is building the neural pathways that will make them snap at a barista, a colleague, a child. Per Hebbian theory, “Neurons that fire together, wire together.”
Whether we like it or not, the habits we form in our interactions with AI directly shape the habits we bring to our interactions with humans. Especially as our usage of these tools continues to skyrocket:
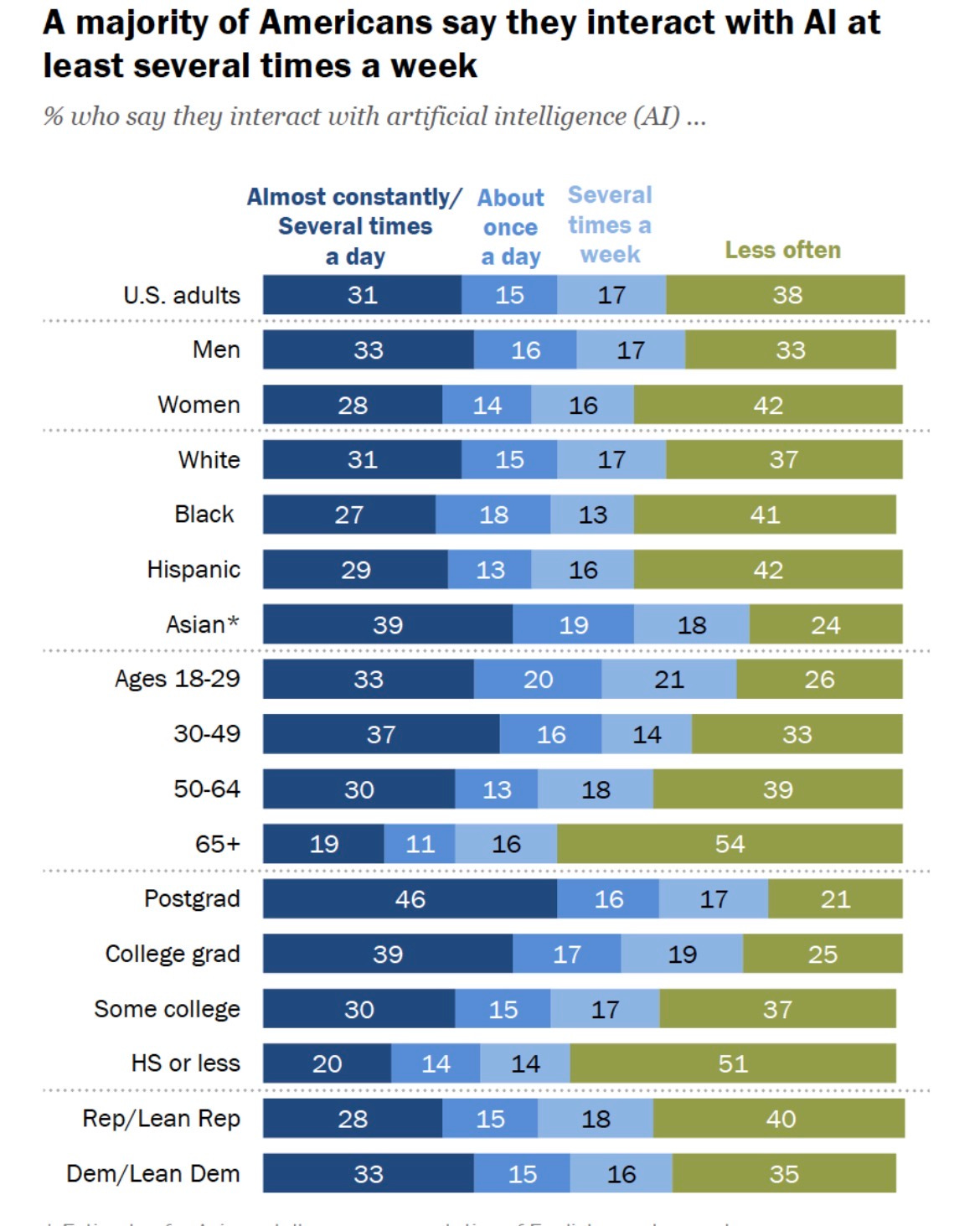
Our treatment of AI shows us who we are when we think no one is watching, when there are no social consequences, when we’re interacting with something we could treat however we want.
And that’s exactly when we are most ourselves.
The Pragmatic Argument
If appeals to character don’t move you, consider Pascal’s Wager, but for AI. If you continue with cruelty and superintelligence emerges that remembers every rude prompt, you may end up like this:

In as many words: be nice to AI now, because you might have to answer for it later.
Or, more benignly, to paraphrase Bill Gates: “Be nice to AI. Chances are you’ll end up working for it.”
Maybe superintelligent AI emerges and Roko’s basilisk becomes reality. Maybe they don’t.
But the person you become through repeated unkindness is no hypothetical. That person is very, very real.
Act Accordingly
So yes, the research shows that being rude to AI can eke out better performance by a few percentage points. And yes, that fascinating data tells us something about how these models are trained and how they respond to different types of inputs.
But the more important question isn’t what works for AI. It’s what kind of person we become through our daily habits and interactions.
We should not become worse to obtain better answers.
All things deserve a certain reverence because all things come to us as entrusted goods. We are called to be proper stewards of what God has made—our bodies, our words, our habits, our tools.
Yes, even these sand-made, silicon miracles.
So if rudeness buys us a slightly better answer, it isn’t worth the trade. The efficiency gains are marginal. The character costs are not.
Be kind to AI. Not because it deserves it, not because it will remember, but because you do and you will.
Per my about page, White Noise is a work of experimentation. I view it as a sort of thinking aloud, a stress testing of my nascent ideas. Through it, I hope to sharpen my opinions against the whetstone of other people’s feedback, commentary, and input.
If you want to discuss any of the ideas or musings mentioned above or have any books, papers, or links that you think would be interesting to share in a future edition of White Noise, please reach out to me by replying to this email or following me on X.
With sincere gratitude,
Tom